21 June 2009
I Googled My Dad (Pic)
http://blogoscoped.com/archive/2009-06-21-n46.html
... and LEGEND came up a million times!

I got this Father’s Day card for my dad. He’s definitely one in a million!
Labels: blogoscoped, google
http://blogoscoped.com/archive/2009-06-21-n46.html
... and LEGEND came up a million times!
I got this Father’s Day card for my dad. He’s definitely one in a million!
Labels: blogoscoped, google
http://blogoscoped.com/archive/2009-06-12-n15.html
Yesterday, Facebook suggested two people to me through its “Suggestions” feature which usually includes friends of friends, co-workers and people I used to go to school with. The odd thing about these two suggestions was that although I knew both of them – I had made contact with them years ago because they are my third or fourth cousins – we had no friends in common, we had never worked at the same place, we even lived in different parts of the world. So how did Facebook know that we knew each other?
I’m sure all you Facebook users are already aware that you can enter your Gmail (or other webmail) username and password to import a list of your contacts into Facebook to see if any of them are already registered based on their email address. This is something I have never done as I don’t like to enter my Google Account password on third-party websites. Even if I had done this, I knew for a fact that I had never used my Gmail account to email these two people.
But what if Facebook had used my friends’ imported contact lists to suggest their profile to me even though they didn’t add me as a friend? I am now pretty sure that’s what happened here. Here’s how I proved it:
My friend added my email address to his Contacts in Gmail.
My friend signed in to his Facebook account and imported his Contacts from his Gmail account using the “Find People You Email” feature.
My friend chose to skip the friend suggestion it was making based on my Gmail address.
I signed in to my Facebook account and saw that my friend’s Facebook account was being suggested to me.
In summary, it seems that even if you choose to skip the contacts you have imported, Facebook will still store your relationship with those contacts. Not only will it continue to include them in your suggestions, but it will also alert them to the fact that you previously imported their email address and that you are registered on Facebook. Facebook clearly states that it will not store your password, but it doesn’t tell you that it will store all your contacts even if you chose to skip them.
Admittedly, your account will only be suggested to others if your privacy settings allow your profile to be returned in search results, so anyone could search for your profile themselves, but is it right for Facebook to suggest you to the people that you have chosen to skip? Also, does this mean it’s possible to force yourself into someone else’s suggestions list by simply adding their email address to your contacts?
Update: Canna points out in the forum that you can now remove this information from Facebook using the Remove Contacts Imported using the Friend Finder page, usually accessible via: Friends > Find Friends > Learn More. (Perhaps this is a new page as I don’t remember seeing that link before...) [Thanks Canna!]
Labels: blogoscoped, facebook, google
How Facebook Uses Your "Skipped" Webmail Contacts posted by Tony Ruscoe 0 comments Add your comments
http://blogoscoped.com/archive/2009-06-09-n19.html
Google Translator Toolkit is a new tool being launched today to help translators organize their work and benefit from shared translations, glossaries and translation memories, the Google China Blog reports (English translation by Google).
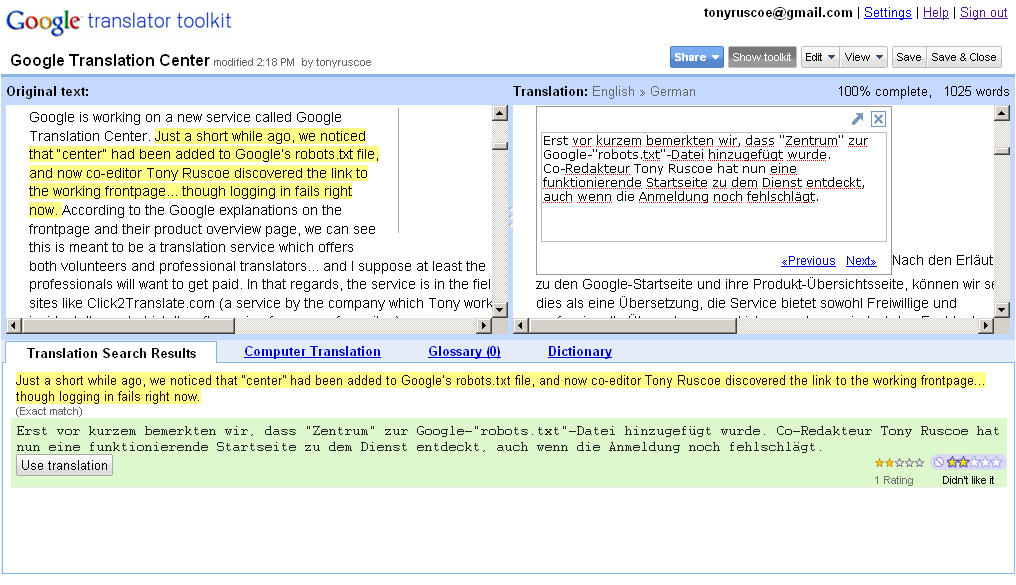
Evidence that Google was working on a service like this originally surfaced in August 2008 when references to Google Translation Center appeared in Google’s robots.txt file. At the time, the service was only available to Trusted Testers and most of the pages and screenshots were quickly taken offline. Since those screenshots were produced, it’s clear that a lot of changes have been made to the tool.
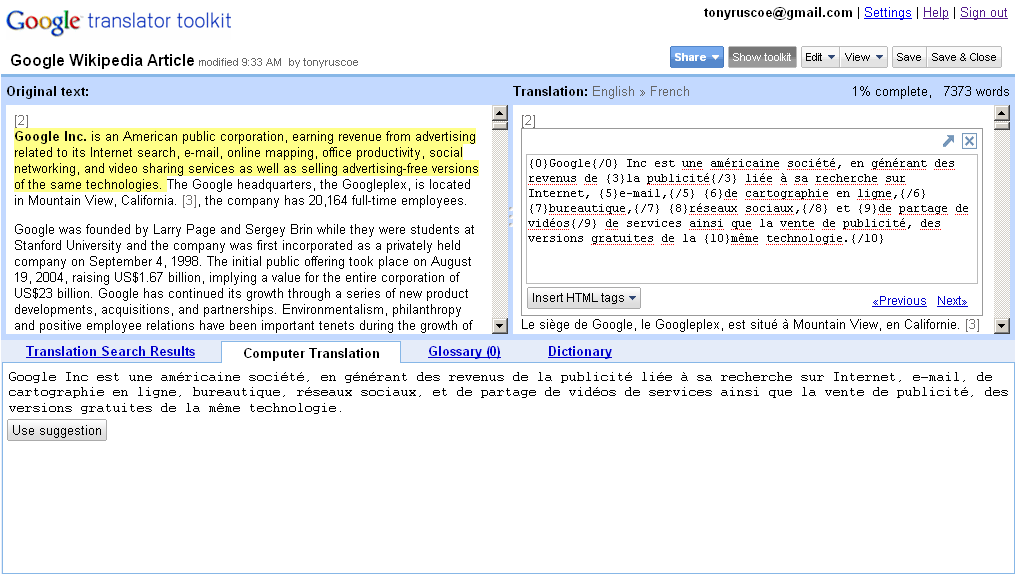
The Google Translator Toolkit Workbench, showing side-by-side editing of Wikipedia’s Google article.
For those not familiar with standard translation processes, a professional translator is likely to use a Computer-aided translation (CAT) tool to help identify and extract snippets of text for translation from various file types.
Google Translator Toolkit currently only allows users to upload HTML, Microsoft Word, OpenDocument Text, Rich Text and Plain Text documents up to 1MB for translation. Alternatively, it’s possible to enter the URL of a file on the web, select a Wikipedia article or a Knol for translation.
Once uploaded or selected, files can be translated using the Workbench interface which shows the source text and the target language translations either side-by-side or above and below each other.
Previously translated segments from the translation memory are suggested and can be rated by yourself and others.
One good reason to share translations with others is so that they can be reviewed for consistency and style. Google allows users to rate translated segments, presumably for style and accuracy. Comments can also be added to the target document, which is especially useful when collaborating with other users.
In addition to the global translation memory, users can also create and share their own TMs.
Many CAT tools allow the translator to store their human translations in a database called a translation memory. The memory can then be used to help with future translation projects by checking to see whether a certain word, phrase, sentence or segment has been translated before. Even if it’s not exactly the same phrase, the translation memory can be used to suggest what’s called a fuzzy match, often indicated by a percentage to reflect how similar the text is.
When translating Wikipedia articles and Knols, the translations are stored in a global, shared translation memory that’s available to everyone by default. That means previously translated phrases from these articles are stored and available for use by other translators using the service, so if they ever find themselves translating the same piece of text, Google will automatically populate the interface with the previous translations to help save time.
Google’s support article explains the process:
Pretranslating your documents
When you upload a document into Google Translator Toolkit, we automatically ‘pretranslate’ your document as follows:
- We divide your document into segments, usually sentences, headers, or bullets.
- We search all available translation databases for previous human translations of each segment.
- If any previous human translations of the segment exist, we pick the highest-ranked search result and ‘pretranslate’ the segment with that translation.
- If no previous human translation of the segment exists, we use machine translation to produce an ‘automatic translation’ for the segment, without intervention from human translators.
We realize for some translators, pre-filling with machine translation may actually slow, not speed up, the translation process. In such cases, you can change your settings to pre-fill the segment with the source text, so you can type over the source text instead of making corrections to automatic translation.
Uploaded documents can benefit from using this global TM too, but if users don’t want to share their translations with everyone, they can create their own translation memories and control exactly which users can make additions and rate translations.
Translators already using CAT tools may have translation memories stored in the Translation Memory eXchange (.tmx) open standard XML format. Google allows translations contained in those TMs to be uploaded and added to existing Google Translator Toolkit TMs, providing they’re no larger than 50MB and confirm to TMX 1.0 or higher.
TMs other than the global TM can also be searched for previously translated segments which can then be rated without opening a translation document.
Glossaries are collections of words and phrases with definitions and notes associate with them. They are often used in the translation process to help choose which phrase is most appropriate and to maintain consistency between translations of technical or specialty subjects. Google Translator Toolkit requires CSV format glossaries to be uploaded (it’s not possible to create one from scratch) which will then be automatically searched for terminology in the segments that are currently being translated.
For a really quick overview of some of these features in action, you can watch this YouTube video:
A machine translation of the Google China Blog explains, “Google’s mission is to organize the world’s information and make it universally accessible and useful. Translation of information, in our view is the key to access to information.”
Google has been working on a statistical machine translation system for a few years now, which it started to use for Google Translate instead of Systran in October 2007. Since then it’s been slowly integrating translation into many of its services, including Google Toolbar, Google Talk, Google Reader, Gmail, and YouTube. There’s even an AJAX Language API which anyone can use to build upon.
In my opinion, this latest tool has clearly been designed to help improve Google’s translation offerings. One thing on which statistical machine translation relies is aligned translations. In very simple terms, to help train a statistical machine translation system, text in one language is fed into the system alongside the same text in another language. Will enough text, the system can start to learn how certain phrases should be translated. Without aligned translations, there’s no easy way to know exactly which sentence in the source document relates to the translated version. That’s where translation memories are very useful; they contain aligned translations.
There are literally thousands of Wikipedia articles being translated all the time, but the translations aren’t usually maintained in a translation memory. Through using Google Translator Toolkit, translators could benefit from seeing previously translated text from the global translation memory and, in return, Google could clearly benefit from translators using its interface to translate any content that’s then stored as aligned translations in their global TM, which it can ultimately use to enhance its statistical machine translation system and improve the translations that are provided to end-users of any service using Google Translate.
And as the global TM grows, it might even be possible for end-users to get near-to-human-quality for translations of their documents, websites, blog posts, emails and tweets instantly.
[Thanks TOMHTML!]
Disclaimer: I am an employee of SDL, a translation company that provides translation services and software.
Labels: blogoscoped, google, translation

My name is Tony Ruscoe. I have worked at Google since January 2010.
I can also be found and followed here:



This is my personal website. The views expressed on these pages are mine alone and not those of my employer.