Blog Archive
30 May 2006
http://blogoscoped.com/archive/2006-05-30-n57.html
Like many webmasters, when Google Sitemaps was released on 2 June 2005, I immediately created and submitted XML sitemaps for all my websites, keeping my fingers crossed that Googlebot wouldn’t find any errors when he finally downloaded them. At the time, Shiva Shivakumar posted to the Official Google Blog:
We’re undertaking an experiment called Google Sitemaps that will either fail miserably, or succeed beyond our wildest dreams, in making the web better for webmasters and users alike. It’s a beta “ecosystem” that may help webmasters with two current challenges: keeping Google informed about all of your new web pages or updates, and increasing the coverage of your web pages in the Google index.
Webmasters expected big things from this experiment. Site owners hoped this would finally mean perfectly crawled, complete indexes of their websites that were regularly updated and would increase their rankings. Most were disappointed and decided to abandon Google Sitemaps almost immediately.
One year since its launch, the interface has changed two or three times and new features have gradually appeared. For any webmasters who ditched Google Sitemaps early on, here’s a quick summary of why there’s possibly more to Google Sitemaps than just getting your site indexed. (For some unknown reason, not all these statistics are available for all websites. It’s probably also worth noting that you can view most of this information by simply adding your website to Google Sitemaps without actually submitting a sitemap.)

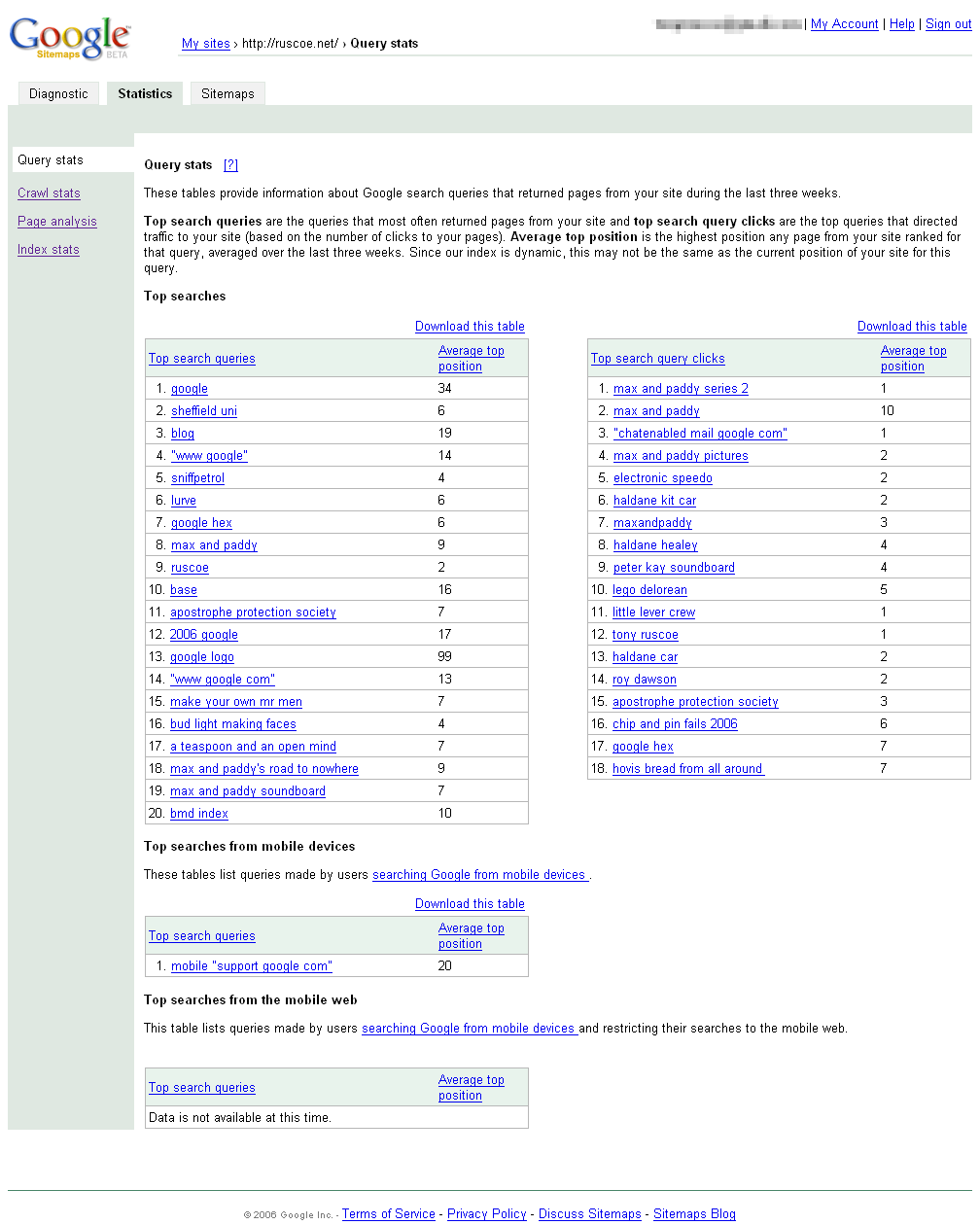
Query stats: Perhaps the most interesting of the statistics provided, these tables show which searches performed over the last three weeks returned pages from your site and what the highest average position was. The top search query clicks table lists which queries resulted in click-throughs to your site (and this should return similar results to any analytics software that shows keyword conversion, such as Google Analytics) and the top search queries table shows which search queries returned your pages in the results where visitors didn’t click through to your pages.

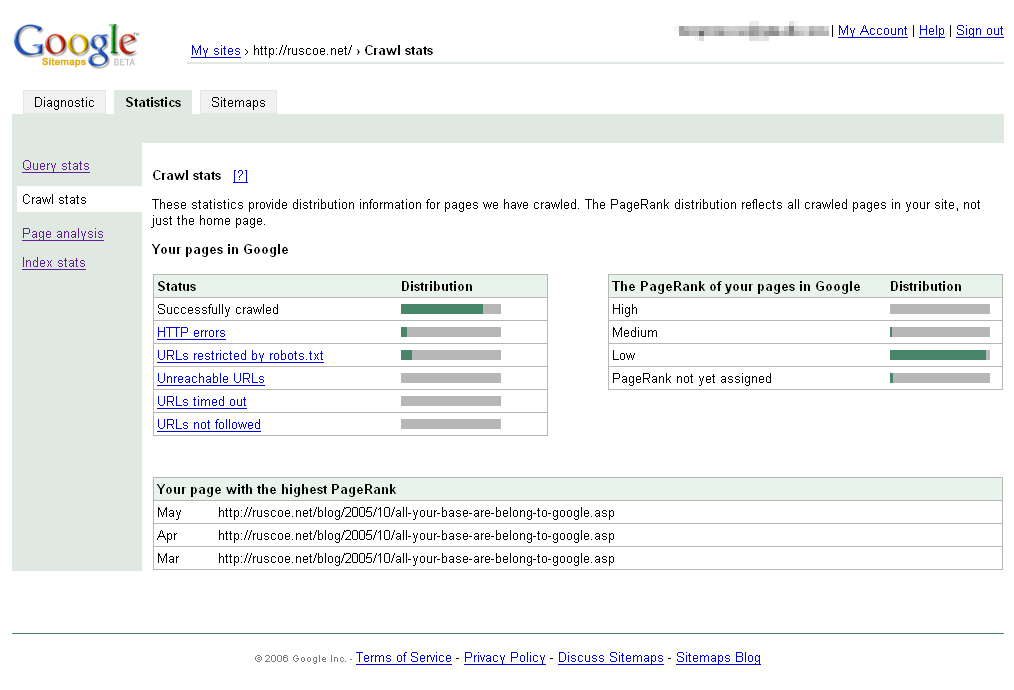
Crawl stats: As well displaying breakdowns for the crawl status of your URLs and how many pages have a high, medium or low PageRank, this section also lists which page on your website has had the highest PageRank for the last three months. For sites with many pages, this can obviously be much quicker than checking each individual PageRank with the Google Toolbar or other tool.

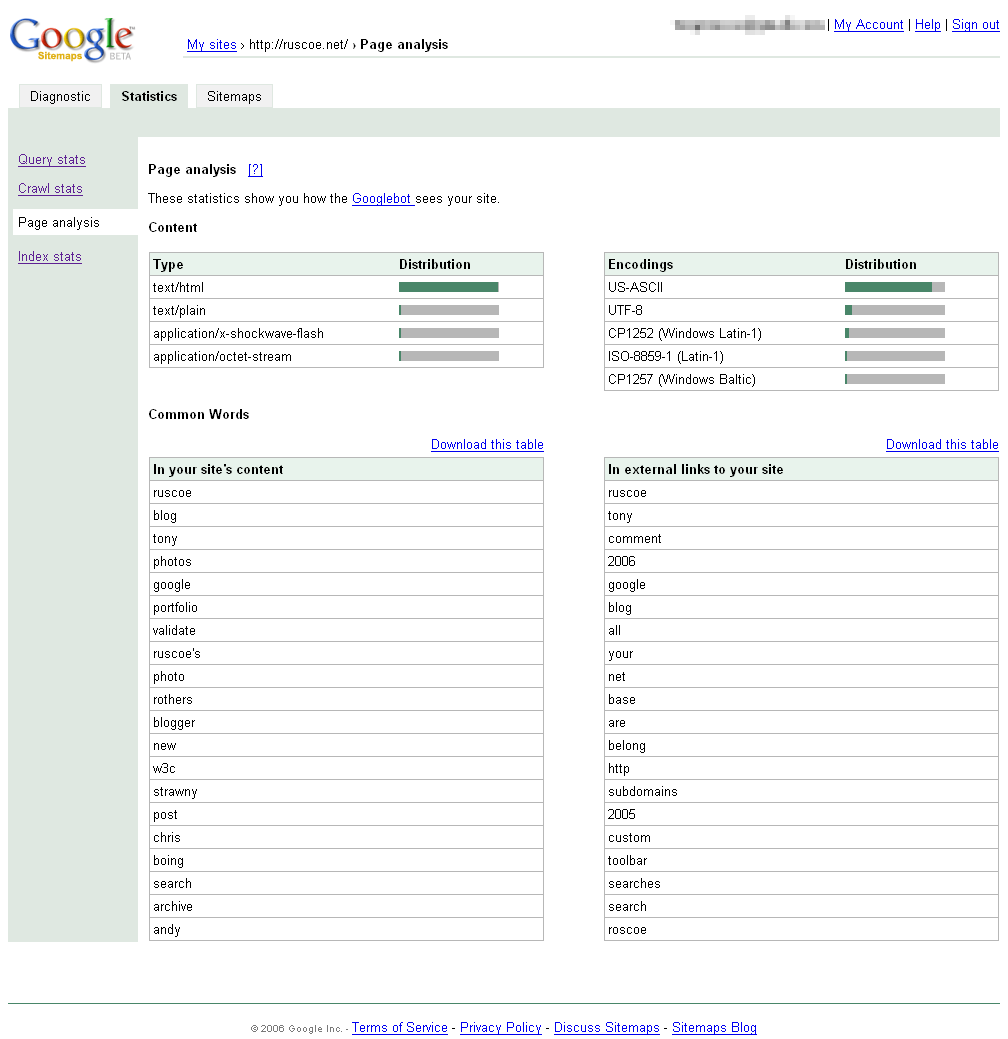
Page analysis: The Content section simply shows the content type and encoding distribution of your pages, but the Common Words section is more interesting, displaying which words most commonly appear on your website and which words are the most common in external links to your site. (Unfortunately, both tables only list words rather than phrases but this should still give you a good idea of why people are finding you and how others are linking to you.)
How could any of this be useful to a webmaster?
- If you’re seeing your key phrases in the top search queries but not in the top search query clicks, you should probably be paying more attention to increasing your rankings for the phrases that aren’t getting the clicks - especially if your average top position is low. If your key phrases don’t appear in either of these lists, you should be reconsidering whether users are actually likely to search for these phrases in the first place. Using tools like Google Trends and the Overture Keyword Selector Tool, you should be able to quickly see which terms could be more popular.
- When optimizing your site for specific key phrases, you could use Crawl stats to identify which page has the highest PageRank and make sure your key phrases appear on that page as they should then carry more weighting in search results.
- If the words appearing in the common words lists aren’t the same as your target keywords, you should probably be re-writing some of your content. And if you’re paranoid about why people are linking to your website, check the common words appearing in external links for any Googlebombs! (If the webmaster for www.whitehouse.gov uses Google Sitemaps he would undoubtedly see “failure” as the most common word appearing in external links.)
Google Sitemaps was created by Google to help them improve their index, in the hope that webmasters would take some of the strain out of crawling the web. Did Google always plan to add the statistics discussed here? I doubt it. I think it’s more likely that they realised webmasters expected something in return for helping Google to improve their index, especially since their indexing and rankings didn’t appear to be improved by submitting sitemaps.
In conclusion, is Google Sitemaps useful or just interesting? Do you use Google Sitemaps? If so, what do you use it for? What do you think the future holds for Google Sitemaps? Has it failed miserably, or succeed beyond their wildest dreams?
Labels: blogoscoped, google
17 May 2006
This post isn’t about the actual service names – like Google Base, Google Calendar, Google Notebook, etc. – it’s about the name that’s passed around by Google Accounts when creating a new account or logging in; the value that’s usually appended to URLs like these:
If you append just any old word to the end of those URLs, you get the standard error for services that do not exist, which looks something like this:
As a pointless exercise, below is a list of values that don’t show that standard error. No fancy scripts were used to create this list – I simply rummaged around for them. (If you’re aware of any that aren’t listed, let me know.)
Update: 11 June 2006 (10:52)
The list of service names has now been moved to a more permanent home where I shall continue to update it as I find new services:
So what’s the point to all this?
Well, I figured that this could be yet another way to try and guess what new Google services are being worked on. For the more recent releases, Google hasn’t been setting up any subdomains, so my Google Subdomains script wouldn’t even have found anything new in advance.
When Google Notebook was first announced at Google Press Day, people set up scripts to monitor the www.google.com/notebook URL so that they could be the first to break the news when it was finally released.
I would guess that before any content pages go live, Google would ‘switch on’ the service in Google Accounts so that people could sign up for the service and login. Having said that, trying to append ‘notebook’ to the ‘NewAccount’ and ‘ServiceLogin’ URLs the day before Google Notebook was actually released still returned the standard error, but for other services – namely Google Base – you were able to try to login months before the service was launched. (For more on discovering Google Base, read my previous post.)
Does anyone fancy setting up a script to randomly test what other services they might be working on?
Labels: google
It was the Google Press Day 2006 last Wednesday. I probably should have blogged about this then.
Anyway, forget about the four new releases, the most exciting part of the webcast was when Sergey Brin (namesake of Google Brin Creator) answered my question about their plans for their statistical machine translation system around 03:32:45 into the webcast.
Tony Ruscoe asked:
Does Google have any plans in the near future to integrate their statistical machine translation system with services such as Google News, Gmail, Google Talk and even Google Search?
Sergey Brin replied:
We actually – for those of you who haven’t heard – we actually developed a statistical machine translation system that won a number of awards last year and came in first on Chinese/English translation as well as Arabic/English translation. And we’re very excited about it. We’d certainly love to get that launched into our products, and we’re working on it.
It was really developed to be as good as possible in terms of the quality of the translation, not as “productionizable” as possible. So, I know it seems trivial, but it would actually take some work to make that happen. But we’re committed to doing it and I believe we will succeed.
No real surprises there then. Although it possibly sounds like Google may be waiting for Moore’s law to kick in before they integrate their statistical machine translation system with more of their services.
Also see Google Press Day posts elsewhere:
Labels: google, personal, translation
Following a brief conversation with Chris the other day, I thought I’d make a short post about what could possibly be the most misinterpreted rule for webmasters... evar!
Don’t use "click here" as link text
– Quality Web Tips, W3C, 2001
47. Don’t use "Click here" as link text
– The Big Website “Don’t!” List, Philipp Lenssen, 4th March 2004
Don’t use "click here" or other non-descriptive link text.
– Top Ten Web Design Mistakes of 2005, Jakob Nielsen, 3rd October 2005
The W3C website also suggests that it’s not strictly correct to use ‘click here’ because “not everyone will be clicking” and continues to give the following advice:
When calling the user to action, use brief but meaningful link text that:
- provides some information when read out of context
- explains what the link offers
- doesn’t talk about mechanics
- is not a verb phrase
In an ideal world, that would be excellent advice. However, when webmasters are faced with the prospect of – let’s say – “challenged” visitors using their websites, things need to be much more obvious. Take the following examples:
- Click here to read my blog.
- Click here to read my blog.
- Click here to read my blog.
- Read my blog.
The first two examples are obviously the worst of the bunch because they don’t even link the main call to action (i.e. ‘read my blog’). According to the advice from the sites referenced above, only the last example would be acceptable. My problem with that link is that I’ve seen users respond with something similar to: “I want to read your blog, but how do I do that?” For a complete beginner, it’s not always obvious that the underlined text is a link and that they can perform the action by clicking it. (This isn’t helped by websites that don’t have underlined links or have underlined text that isn’t linked!)
I think that for any website that could be used by complete novices to the Internet, my preference would be to use the third example above. And I think it’s fair to say that it probably wouldn’t offend the more savvy users either. (Sure, not everyone will be clicking, but not everyone will be walking across the road when those American crossing signs say “WALK” or “DONT WALK” – yet those people have learnt to know what it means...)
In conclusion, if you know what you’re doing and why you’re doing it, using ‘click here’ in your link text is fine by me.
P.S. It’s also fine to start a sentence with ‘Because’, ‘And’ or ‘But’ regardless of what your English teacher may have told you!
Labels: development, personal, rant
12 May 2006
Since Google’s disappointingly easy Da Vinci Code Quest has now finished, it’s good to see there’s a new game in town. The Web Riddle written by Sam Davyson and friends requires some basic HTML knowledge and quite a bit of lateral thinking to play. (For some background information, see Sam’s original post.)
Currently containing only eight levels, Sam promises in his recent blog post that there are more to come, with maybe even a few written by yours truly!
There are no prizes here; the only reward is the pleasure you’ll get from being incredibly smug when your colleagues take hours to solve the riddles that only took you a couple of minutes...
Labels: links
8 May 2006
I’ve been developing websites for several years now. In the early days, I was just playing with static HTML (see my early efforts if you fancy a laugh) but around six years ago I read a copy of Active Server Pages for Dummies, learnt how to develop dynamic, e-commerce websites and never looked back.
Writing websites powered by clever code is great, but something you should never do is compromise the security of your website or server. I can understand why Google occasionally has problems with security because their websites can be incredibly complex, but other companies should be aware of the risks involved with hiring developers who write sloppy code that could put the privacy of their customer details at risk.
A few years ago, I ordered some wine from a well known wine merchant’s website. After ordering, I noticed that my receipt simply contained my order number in the query string at the end of the URL, something like this:
https://www.example.com/checkout/printreceipt.asp?OrderNo=100000000845572
As an experiment, I simply changed the OrderNo parameter and discovered that I could view the details for every order in their database – which included the personal details of all their customers. Not only that, but I could also use the same technique to change the delivery address for any order in their system without even being logged in!
I notified the website in question – which incidentally claimed to be “totally committed to protecting your privacy” – and received my first response over one week later. “The fault was created by our old web design agency and unfortunately no one picked up on it,” explained their Online Marketing Manager, “our new agency have promised to have a secure fix in place by Friday night and it is our number one priority.” During this time, customers’ details were freely available to anyone with a bit of simple web programming knowledge and they didn’t even send me a free bottle of wine for notifying them directly instead of running to Watchdog!
Today I stumbled across another e-commerce site with several serious security flaws. I’d usually email the company whose website it was to give them some friendly advice, but I shan’t be doing that in this case because the website belongs to a competitor who ripped off the layout, graphics, content and code from one of my websites and has kindly ignored our ‘Cease and Desist’ letters!
Instead, just to ease my conscience a little bit, here are just a few tips for making sure that your website is safer than theirs.
- Don’t rely on client-side validation – most browsers allow you to switch off client-side scripting, so make sure your website handles this gracefully.
- Don’t save any uploaded files to your webspace – not even if they’re saved to folders with randomly generated names, and especially not if your users can upload scripts which can be executed – i.e. ASP, PHP, CGI, etc.
- Don’t store your customer database on your webspace – but if you absolutely have to do this, I’d suggest password protection and a random filename.
- Validate user input server-side – especially if you’re using parameters passed in via the query string or form fields to create SQL queries on the fly, otherwise your visitors could use SQL Injection to update or delete the entire contents of your database.
- Secure any admin areas properly – make sure they’re password protected so that only authorized people can access them, don’t just assume that people will never guess the URL!
I know that we can all make mistakes, but many smaller companies are hiring cheap, freelance developers who don’t care about whether their code is secure because the customer doesn’t know how to test it; by the time a security flaw is revealed, the developer’s already been paid and the company could be left with an expensive problem on their hands – especially if a malicious visitor has deleted the entire contents of their database or modified the website.
So, my final question is this: Would it be wrong of me to switch off client-side scripting in my browser, upload an ASP file to their webspace that, when executed, lists every file and folder in the root of the website, then proceed to download a copy of their files, including their customer database and confidential PDFs regarding their budgets?
(Surely that’s not wrong, is it? Not when you consider what I could have done...)
Anyway, here endeth the lesson. Any questions (or answers)?
Labels: development, personal, rant
4 May 2006
We went to watch Cats on Tuesday night at the Lyceum Theatre in Sheffield. (I would’ve posted about this earlier, but I was waiting for Chris to write an in-depth review so I could write a quick post and link to it, but it looks like he’s too busy talking about flowers and hot days...)
I like to think that I’m pretty good at following the plots of plays and musicals. However, it usually helps when there’s a plot to follow. I later learned from Wikipedia that I was almost there: the cats were having their annual Jellicle Ball at a junkyard to make the Jellicle Choice and announce the cat who can be reborn. And that’s it. (Except when they say “reborn” they actually mean “die”.) As the Wikipedia entry also says, “While CATS is often criticized for its lack of plot, it does have a minimal story used to string its musical numbers together.”
The production was very well presented, so it’s a shame that Andrew Lloyd Webber didn’t spend more time on the storyline really. I guess the producers felt that the lack of plot meant that they should add extra dance sequences and reprises of songs to give the audience their money’s worth. (The fact that the cats came to interact with the audience was a nice touch though.)
I noticed one of the ‘Jellicle’ cats (possibly The Magical Mr. Mistoffelees, although I can’t be sure because they all looked quite similar) had been to the Wayne Sleep School of Dance and learnt Wayne’s favourite dance move. You know the one I’m talking about – I’ve mentioned it before – it’s the one where he spins around as fast as he can on one leg. It got a huge round of applause again anyway. (Why the contestants on Strictly Dance Fever don’t just do that each week I’ll never know!)
My conclusion? I’m glad I’ve seen it. I was a bit unsure about going at first as I get the impression that all ALW’s shows are too pantomime-like. Having said that, any show that’s still running after 25 years must be worth seeing.
Labels: music, personal, theatre